This document is aimed to guide in the process of creating a linked data (LD) version of a lexical resource, particularly a bilingual dictionary. It contains advice on the vocabulary selection, RDF generation process, and publication of the results. As a result of publishing the data as LD, the converted language resource will be more interoperable and easily accessible on the Web of Data by means of standard Semantic Web technologies. The process described in this document has been illustrated with real examples extracted from Apertium RDF, an open-source machine translation system which has their data available for download.
This report constitutes an update of a previously published one: Guidelines for Linguistic Linked Data Generation: Bilingual Dictionaries. The previous version, which dates to 2015, used the initial lemon model [LEMON, LEMON_PAPER] as core representation mechanism, while this updated version uses the more recent Ontolex lemon [ONTOLEX, ONTOLEX_PAPER]. Both guidelines remain valid, but we recommend using this version for new developments based on Ontolex lemon. The current report is lagely based on the book chapter "Converting language resources into linked data" by Cimiano et al. [CONV] that we recommend for a more complete and scholarly view on the matter, while we recommend the present guidelines for a quicker and more practical reference.
There are a number of ways that one may participate in the development of this report:
- Mailing list: public-bpmlod@w3.org
- Wiki: Main page
- More information about meetings of the BPMLOD group can be obtained here
- Source code for this document can be found on Github.
Description of the type of resource
The type of language resources covered in this document is bilingual electronic dictionaries. A bilingual dictionary provides translation equivalents of words and phrases (and examples of usage) of one language in another language. They can be unidirectional or bidirectional, allowing translation, in the latter case, to and from both languages. In addition to the translation, a bilingual dictionary usually indicates the part of speech, as well as the gender, verb type, declination model and other semantic, syntactic, and grammatical properties to help a non-native speaker use the word.
We refer to bilingual dictionaries that have data in a machine-processable format, no matter whether it is stored locally or is accessible on the Web (e.g. for download). We assume that the data is represented in a structured or semi-structured way (e.g. relational database, XML, CSV, etc.).
The topic is illustrated by examples from the conversion of the Apertium dictionaries into RDF [AP_RDF]. Apertium [AP_PAPER] is a free/open-source machine translation platform originally designed to translate between closely related languages, although it was later expanded to treat more divergent language pairs. The Lexical Markup Framework [LMF] versions of their linguistic data are available here and they were used as starting point for the first RDF version of the Apertium dictionaries [AP-RDF_PAPER], based on the original lemon model. A more recent version of Apertium RDF was later developed by following Ontolex lemon [AP_RDF_V2_PAPER].
Selection of vocabularies
- We propose Ontolex lemon (LExicon Model for ONtologies) [ONTOLEX, ONTOLEX_PAPER] to model the RDF representation of the linguistic descriptions contained in bilingual dictionaries. Ontolex lemon has been designed to extend the lexical layer of ontologies with as much linguistic information as needed, and to provide it as LD on the Web. It is made up of a series of modules, of which we use the following three:
- core, where lexical entries, forms, and lexical senses are defined,
- lime, where
lexiconis defined, - vartrans. We mainly use two classes:
TranslationandTranslationSet.Translationis a reification of the relation between two lexical senses associated to entries in different languages. Using a reified class allows us to describe attributes of theTranslationobject, such assourceandtargetof the translation,category, to determine the type of translaiton, as well as attributes denoting provenance (see below).TranslationSetis a group of translations, typically those coming of the same bilingual dictionary.
- The use of lemon is complemented with Lexinfo [LEXINFO]. Lexinfo is an ontology of types, values and properties that is used with the lemon model, partially derived from ISOcat. We use Lexinfo as a catalog of data categories (e.g. to denote gender, number, part of speech, etc.).
- Translation categories are represented by pointing to an external catalog (e.g. to state that a translation is a "cultural equivalent"). We propose the one at [TRCAT] but any other could be used instead.
- Other extendedly used vocabularies such as Dublin Core [DC] are used to attach valuable information about provenance, authoring, versioning, or licensing.
- Finally, the Data Catalogue Vocabulary [DCAT] is used to represent other metadata information associated to the publication of the RDF dataset.
| owl | <http://www.w3.org/2002/07/owl#> |
| rdfs | <http://www.w3.org/2000/01/rdf-schema#> |
| ontolex | <http://www.w3.org/ns/lemon/ontolex#> |
| lime | <http://www.w3.org/ns/lemon/lime#> |
| vartrans | <http://www.w3.org/ns/lemon/vartrans> |
| lexinfo | <http://www.lexinfo.net/ontology/3.0/lexinfo#> |
| trcat | <http://purl.org/net/translation-categories#> |
| dc | <http://purl.org/dc/elements/1.1/> |
| dct | <http://purl.org/dc/terms/> |
| dcat | <http://www.w3.org/ns/dcat#> |
| apertium | <http://linguistic.linkeddata.es/id/apertium/> |
RDF generation
For the generation and publication processes we have followed existing recommendations [GUIDE_MLD, CONV], adapted to this particular case.
The first step in the publication of Linked Data is to analyse and specify the resources that will be used as source of data, as well as the data model(s) used within such sources. The analysis covers two aspects
Analysis of the data sources
The result of this phase is strongly dependent on the particular data source and its representation formalism. The general advice would be to get a good understanding of how the original dictionary is represented in order to define proper conversion rules of the original data into RDF.
Regarding our illustrative example (Apertium EN-ES dictionary), the model used for representing the data is [LMF]. The following lines of code illustrate how the content is represented in LMF/XML for a single translation:
<Lexicon>
<feat att="language" val="en"/>
...
<LexicalEntry id="bench-n-en">
<feat att="partOfSpeech" val="n"/>
<Lemma>
<feat att="writtenForm" val="bench"/>
</Lemma>
<Sense id="bench_banco-n-l"/>
</LexicalEntry>
...
</Lexicon>
<Lexicon>
<feat att="language" val="es"/>
...
<LexicalEntry id="banco-n-es">
<feat att="partOfSpeech" val="n"/>
<Lemma>
<feat att="writtenForm" val="banco"/>
</Lemma>
<Sense id="banco_bench-n-r"/>
</LexicalEntry>
...
</Lexicon>
...
<SenseAxis id="bench_banco-n-banco_bench-n" senses="bench_banco-n-l banco_bench-n-r"/>
...
Modelling
The first step in the modelling phase is the selection of the domain vocabularies to be used, as described in Section 2 (Selection of vocabularies). The next thing is to decide how the representation scheme of the source data has to be mapped into the new model. In the case of bilingual dictionaries, each dictionary is converted into three different objects in RDF (regardless if the original data comes in one or several files):
- Source lexicon
- Target lexicon
- Translation Set
Going into the details of the model, Figure 2 illustrates the representation scheme used for a single translation, in terms of ontolex and the vartans module:
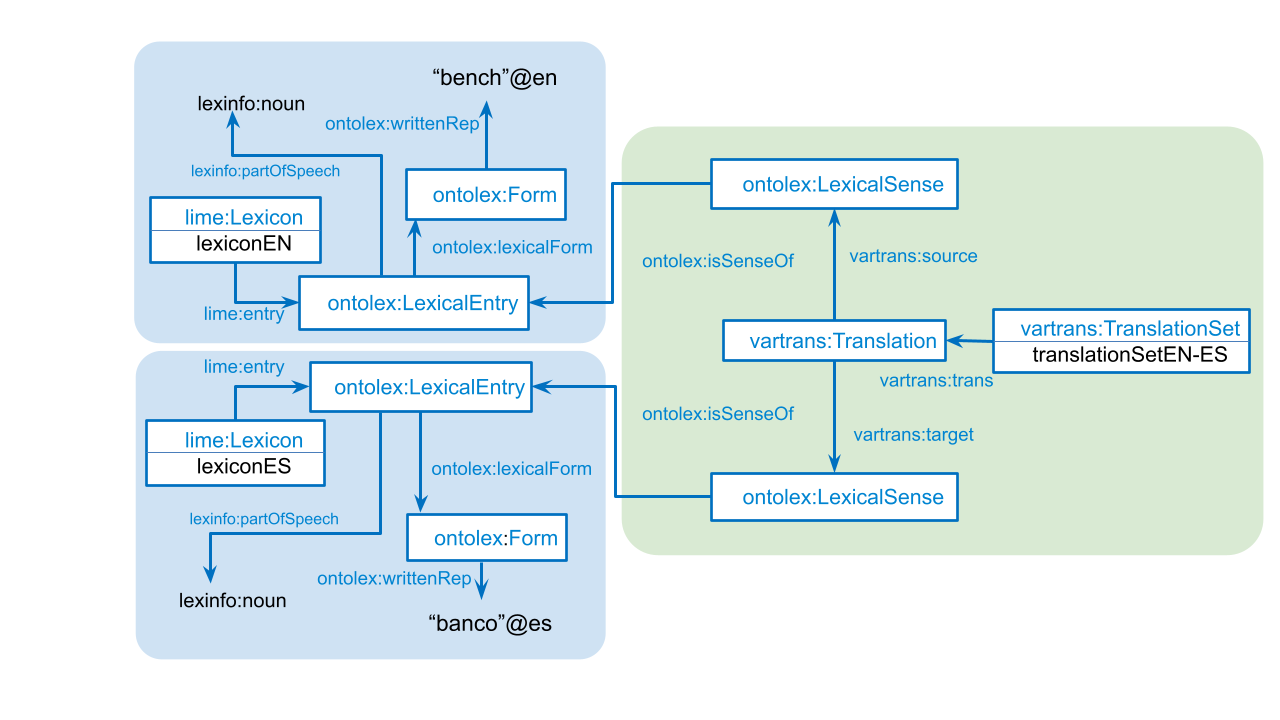
ontolex:LexicalEntry and its associated properties are used to account for the lexical information, while the vartrans:Translation class puts them in connection through ontolex:LexicalSense. Other simpler options are also possible, such as connecting the lexical entries directly without defining "intermediate" senses through the vartrans:translatableAs property (see VT). Nevertheless, translations occur between specific meanings of the words and the use of the vartrans:Translation as a connector between two ontolex:LexicalSense allows us to represent this explicitly.
URIs design
Among the different patterns and recommendations that are available for defining URIs, we propose the one at [ISA_URIS] although others could be used instead. In short, the ISA pattern is as follows: http://{domain}/{type}/{concept}/{reference}, where {type} should be one of a small number of possible values that declare the type of resource that is being identified. Typical examples include: 'id' or 'item' for real world objects; 'doc' for documents that describe those objects; 'def' for concepts; 'set' for datasets; or a string specific to the context, such as 'authority' or 'dcterms'.
In our example, the main components (lexicons and translation set) of the Apertium RDF bilingual dictionary are named as follows:
English lexicon: http://linguistic.linkeddata.es/id/apertium/lexiconEN Spanish lexicon: http://linguistic.linkeddata.es/id/apertium/lexiconES English-Spanish translation set: http://linguistic.linkeddata.es/id/apertium/tranSetEN-ESIn order to construct the URIs of the lexical entries, senses, and other lexical elements, we preserved the identifiers of the original data whenever possible, propagating them into the RDF representation. Some minor changes have been introduced, though. For instance, in the source data (see Example 1) the identifier of the lexical entries ended with the particle "-l" or "-r" depending on their role as "source" or "target" in the translation. In our case, the directionality is not preserved at the Lexicon level (but in the Translation class) so these particles are removed from the name. In addition, some other suffixes have been added for readability (this step is optional): "-form" for lexical forms, "-sense" for lexical senses, and "-trans" for translation. See Section 4 (Generation) for particular examples.
Generation
This activity deals with the RDF transformation of the selected data sources using the representation scheme chosen in the modelling activity. Technically speaking, there are a number of frameworks and tools that can be used to assist the developer in this task (see here for an extensive list). The final choice depends on the format of the data source and the preferences and skills of the person deveoping the conversion. In our running example, Open Refine (with its RDF extension) is a suitable choice to transform XML data into RDF, but other tools and frameworks are possible.
As a result of the transformation, three RDF files were generated, one per component (two lexicons and a translation set). The following examples contain the RDF code (in turtle) of a single translation. The three pieces of code come from the EN and ES lexicons and from the EN-ES translation set, respectively, of the Apertium example:
apertium:lexiconEN a lime:Lexicon ; dc:source <http://hdl.handle.net/10230/17110> . ... apertium:lexiconEN lime:entry apertium:lexiconEN/bench-n-en . apertium:lexiconEN/bench-n-en a ontolex:LexicalEntry ; ontolex:lexicalForm apertium:lexiconEN/bench-n-en-form ; lexinfo:partOfSpeech lexinfo:noun . apertium:lexiconEN/bench-n-en-form a ontolex:Form ; ontolex:writtenRep "bench"@en .
apertium:lexiconES a lime:Lexicon ; dc:source <http://hdl.handle.net/10230/17110> . ... apertium:lexiconES lime:entry apertium:lexiconES/banco-n-es . apertium:lexiconES/banco-n-es a ontolex:LexicalEntry ; ontolex:lexicalForm apertium:lexiconES/banco-n-es-form ; lexinfo:partOfSpeech lexinfo:noun . apertium:lexiconES/banco-n-es-form a ontolex:Form ; ontolex:writtenRep "banco"@es .
apertium:tranSetEN-ES a vartrans:TranslationSet ; dc:source <http://hdl.handle.net/10230/17110> ; ... apertium:tranSetEN-ES vartrans:trans apertium:tranSetEN-ES/bench_banco-n-en-sense-banco_bench-n-es-sense-trans . apertium:tranSetEN-ES/bench_banco-n-en-sense a ontolex:LexicalSense ; ontolex:isSenseOf apertium:lexiconEN/bench-n-en . apertium:tranSetEN-ES/banco_bench-n-es-sense a ontolex:LexicalSense ; ontolex:isSenseOf apertium:lexiconES/banco-n-es . apertium:tranSetEN-ES/bench_banco-n-en-sense-banco_bench-n-es-sense-trans a vartrans:Translation ; vartrans:source apertium:tranSetEN-ES/bench_banco-n-en-sense ; vartrans:target apertium:tranSetEN-ES/banco_bench-n-es-sense .As reproducibility is an important feature, the mappings between the original data and the new RDF-based model, as well as the scripts for the RDF generation, should be recorded and stored to enable their later reuse.
Publication
The publication step involves: (1) dataset publication, (2) metadata publication, and (3) enabling effective discovery. Here we focus on the second task (metadata publication). In the context of LD, there are two major vocabularies for metadata of datasets and catalogs: VoID (Vocabulary of Interlinked Datasets) [VOID], and DCAT (Data Catalogue Vocabulary) [DCAT]. In our running example, we use DCAT for describing the elements generated in the RDF conversion of bilingual dictionaries. In any case, DCAT can be complemented with VoID or other vocabularies if required.
--------------- TO BE UPDATED... ---------------
The RDF version of Apertium EN-ES was published in Datahub. The Datahub platform created a metadata file for the Apertium EN-ES dataset based on DCAT. We extended such metadata file with additional missing information such as provenance, license, and related resources. The extended metadata was published as part of the Apertium EN-ES Datahub entry. The following lines are a fragment of it:
<dcat:Dataset rdf:about="http://linguistic.linkeddata.es/set/apertium/EN-ES"> <owl:sameAs rdf:resource="http://datahub.io/dataset/apertium-en-es"></owl:sameAs> <dct:source rdf:resource="http://hdl.handle.net/10230/17110"></dct:source> <dct:license rdf:resource="http://purl.oclc.org/NET/rdflicense/gpl-3.0"></dct:license> <rdfs:seeAlso rdf:resource="http://dbpedia.org/resource/Apertium"></rdfs:seeAlso> <rdfs:seeAlso rdf:resource="http://purl.org/ms-lod/UPF-MetadataRecords.ttl#Apertium-en-es_resource-5v2"></rdfs:seeAlso> </dcat:Dataset>
Recommendations
- Separate the monolingual lexicons from the translation sets (different graphs and/or files).
- Lexical senses should play the role of connectors between translations and lexical entries.
- Be consistent with the rules for naming and URIs creation.
- Keep the identifiers of the legacy data if possible, but remove indicators of directionality if any (e.g. "l", "r", "left", "right", ...)