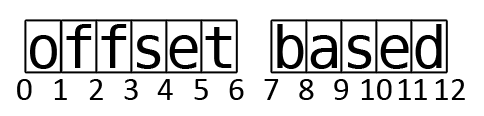This document describes best practices to follow for the generation of Linked Data text corpora, using the NLP Interchange Format (NIF). NIF is an RDF/OWL-based format that aims to achieve interoperability between NLP tools, language resources and annotations. It can be used to assign URIs to strings and annotate the resulting resources. The Brown corpus serves as example throughout these guidelines.
There are a number of ways that one may participate in the development of this report:
More information about meetings of the BPMLOD group can be obtained
here
Source code
for this document can be found on Github.
Introduction
NIF is an RDF-based format for describing strings in text documents. The format - its classes and properties are formally defined within the NIF Core Ontology. The core classes of NIF important to this tutorial are:
String: A string contained in the document or the document's content itself, described by beginIndex and endIndex.
Context: A string that serves as context for its substrings. It usually describes the whole document's text and contains it in the nif:isString property.
Sentence: A String which represents a sentence.
Phrase: A String which represents a phrase.
Word: A String which represents a single word.
Looking at a mirror of the Brown corpus, we can see there are 500 XML documents. Every document contains some metadata as well as a number of sentences with annotated words, including their part-of-speech tags. Consider this example, which is the first sentence of the first document (http://brown.nlp2rdf.org/corpus/a01.xml) of the corpus:
The Fulton County Grand Jury said Friday an investigation of Atlanta's recent primary election produced ``no evidence'' that any irregularities took place.
Selection of vocabularies
In the following we list the reference models used during the conversion and provide the namespace, the prefix adopted throughout this document (in bold) and the URL to the model specification.
NIF was developed to allow NLP tools to exchange text annotations in RDF. This requires a way to make text strings referenceable by URIs to be able to use them as resources of RDF statements. The algorithm to create a URI for a specific string contained in a document is called a URI scheme. This scheme needs a number of parameters to create a URI, namely:
the URI of the document itself, in the following addressed as prefix
the character indices of beginning and end of the string to address
a separator between the prefix and string position identifier
Character indices in NIF are counted offset based, starting at zero before the first character and counting the gaps between the characters incrementally until after the last character of the referenced string.
Visualisation of offset based character counting
The canonical URI scheme of NIF, nif:OffsetBasedString, is based on these character indices. Hence, the following URI can address the substring "Fulton" in our example sentence of the document http://brown.nlp2rdf.org/corpus/a01.xml:
http://brown.nlp2rdf.org/lod/a01.ttl#offset_4_10
The prefix of this URI is colored red, marking the URI of the corpus document that contains our example sentence, is recommended to end on slash ('/'), hash (‘#’) or on a query component ('?'). The scheme identifier is marked blue and states that a range of characters is identified. The fragment identifier, colored green, describes the start and end offset of the identified string. The combination of scheme identifier and fragment identifier (in our case ‘offset_4_10’) is also called identifier part. The URI scheme, as it is defined, helps to i) uniquely identify Strings and ii) compute (if needed) begin and end offsets out of the string URI.
String annotation
After assigning URIs to meaningful strings of the corpus, these URIs can be annotated using the NIF core ontology. The central class is nif:String, the class of all words consisting of Unicode characters.
Strings offer properties to describe their content (the Unicode character string itself, via nif:anchorOf) and their position according to other strings with text indices (via nif:beginIndex and nif:endIndex, mandatory) as well as various semantic information, like part-of-speech tags, sentiment values or word stems.
Context
nif:Context is a subclass of the nif:String class. The Context represents the whole document. It serves as a reference point to all other substrings. It must have either a nif:isString property which contains the string content of the document or a nif:contextStringRef property pointing to a URL where the same string content can be obtained. In both cases, the string content must be cleaned from any markup and encoded as Unicode. Furthermore these unicode strings should be in Unicode Normal Form C (NFC), barring compelling reasons to use Normal Form D. In our case it looks like this when embedding the primary text data:
<http://brown.nlp2rdf.org/corpus/a01.xml#offset_0_161>
a nif:String , nif:Context , nif:OffsetBasedString ;
nif:isString """The Fulton County Grand Jury said Friday an investigation of Atlanta's recent primary election produced ``no evidence'' that any irregularities took place. [...]"""^^xsd:string ;
nif:beginIndex "0"^^xsd:int ;
nif:endIndex "161"^^xsd:int ;
nif:sourceUrl <http://icame.uib.no/brown/bcm.html> .
Here the equivalent context representation using a stand-off annotation approach:
nif:beginIndex of the Context is always 0, because it represents the whole document. The nif:endIndex simply is the length of the string.
Sentences, Words and other strings
Substrings of the nif:Context can be anything from a single word to sentences and paragraphs. They link to the relevant Context resource via nif:referenceContext. Beginning and end indices always refer to the string content represented by the context.
The first sentence of our document would be presented as follows:
<http://brown.nlp2rdf.org/corpus/a01.xml#offset_0_155>
a nif:String , nif:Sentence , nif:OffsetBasedString ;
nif:anchorOf """The Fulton County Grand Jury said Friday an investigation of Atlanta's recent primary election produced ``no evidence'' that any irregularities took place."""^^xsd:string ;
nif:referenceContext <http://brown.nlp2rdf.org/corpus/a01.xml#offset_0_161> ;
nif:beginIndex "0"^^xsd:int ;
nif:endIndex "155"^^xsd:int .
Note that the property nif:anchorOf may be used to explicate the annotated string. Words are annotated the same way. The first word of the document is annotated as follows:
Words may link the following word as well as their sentence. Further annotations can be added to words. Note the nif:oliaLink property, that assigns a part-of-speech (POS) tag to the word.
Annotations - general concepts
NIF 2.1 distinguishes between two general kinds of annotations:
text span annotations (nif:TextSpanAnnotation) highlight portions of text to carry an intrinsic characteristic that does not need to be specified further using property assertions (e.g. marking a word or phrase as a mentioning of a named entity, marking a phrase as direct quotation)
property annotation assertions (nif:PropertyAssertionAnnotation) associate a portion of a text with fact assertions (e.g. providing a part-of-speech annotation for a word or linking an occurrence of a named entity in the text to an information resource representing the entity, for instance a DBpedia resource)
Also, it is often important to provide provenance and confidence information for represented annotations, especially when they were generated (semi-)automatically by NLP-tools. A generic property nif:confidence is provided to express confidence values. To express provenance, appropriate elements of the PROV ontology should be used, particularly prov:wasGeneratedBy and prov:wasAttributedTo. When several annotation are to be expressed for the same NIF string instance, additional resources typed nif:AnnotationUnit might need to be introduced to associate provenance and confidence information unambiguously. The following paragraph on named entity annotation gives opportunity to elucidate these concepts.
Named Entities
Depending on how much information is available, named entities have to be annotated in different ways. If some annotator or tool was just able to spot the occurrence of a named entity without identifying it conclusively, nif:EntityMention is called for (which is a plain text span annotation).
In most cases, you will have the coarse-grained class the entity belongs to (i.e. if it is a Person, a Location, an Organization etc). To annotate these, please refer to the NERD ontology. Like in the case of OLiA, it maps different named entity types to single resources, increasing interoperability. The relevant property for annotation is nif:taNerdCoreClassRef.
On the other hand, if you have a direct link to, for example, the respective DBpedia resource, you should of course link this one, too. For this purpose you can use the itsrdf:taIdentRef property from the Internationalization Tag Set (ITS) Version 2.0 vocabulary which enables integration of automated processing of human language into core Web technologies. ITS 2.0 provides properties, also called data categories, which can be used to express information related to machine translation, terminology, text analysis, provenance, confidence, etc. All ITS 2.0 properties are compatible and can be used in combination with NIF.
Although there are no named entity annotations in the Brown corpus itself, we will add some for in the following example, since three separate pieces of annotation information is added to the same NIF string, nif:AnnotationUnits to clearly associate provenance information:
Part-of-speech annotations are handled in NIF via OLiA. In general, OLiA is a set of ontologies that map corpus or tool specific annotations to a reference model. While NIF aims to provide syntactic interoperability between NLP tools and relevant corpora, OLiA provides a component of semantic interoperability by mapping the disparate annotation terms used by different tools and corpora to entities of a common reference model.
Differences in annotation terminology range from minor differences in the choice of tag names to more fundamental variations. For each of these different annotation schemes, OLiA provides an Annotation Model, as well as a Linking Model to the common Reference Model. The reference model contains basic POS classes the abstract from specific POS as used in single tagsets.
To transform POS annotations into OLiA, visit the OLiA page and search for the annotation model that matches your tagset. In our case, it is the Brown annotation model. Now POS tags found in the corpus can just be appended to the annotation model’s URI:
In practice, aggregations of different corpora and tool outputs can then be queried for links to the OLiA reference model. This allows, for example, to aggregate the output of an NLP tool that using two different tagset and query it for all words of the type ``adjective''.