RDF Generation
Data modelling
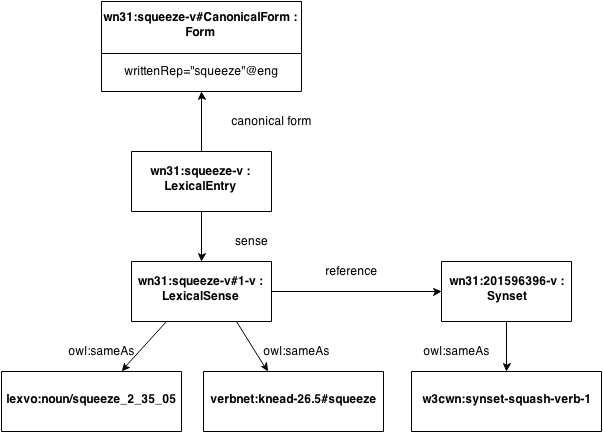
An example of the modelling a single word and synset and links to other resources
It is not trivial to apply lemon to the case of a WordNet as there is no clear ontology in WordNet. Clearly, WordNet’s words can be regarded as lemon lexical entries and the word senses correspond well to lemon’s lexical senses. WordNet has lemmas and a separate list of variants of these, and as such we recommend creating a canonical form for each lemma and a form object for each of these variants. Since there is currently no indication in WordNet of what grammatical properties these variants have, we do not recommend attaching additional properties to these variants/forms. As lemon is a model for ontology-lexica, the main question is what the reference of the lexical senses should be. We recommend regarding WordNet’s synsets as ontological references, but instead of assigning them a formal ontological type (e.g., class, property or individual), we introduce a new type Synset as a subclass of Concept in SKOS.
This allows the nature of synsets to be captured without ontologizing the semantic network. Similarly, we introduce relations such as hypernymy, meronymy etc. as new properties rather than attempt to relate them to existing ontological properties such as OWL’s subClassOf. In order to capture the new properties, an ontology has been created at http://wordnet-rdf.princeton.edu/ontology
URI design
Another key question concerns the identifiers to use for each element in the data. In order to enable browsability, we recommend that each entry and each synset has its own page and thus it own URI. We do not recommend distributing WordNets as a single flat file as they are large and this impedes their access on the web. You should assign new identifiers using the existing identifiers in your wordnet. Furthermore, as wordnets have released several versions and are still under development, we consider it important to include the version number in the URI. As such, we recommend the following scheme for URIs, as exemplified below:
- Each lexical entry is represented by means of the URL-encoded lemma and then a dash followed by the part-of-speech as a single letter (i.e., ‘n(oun)’, ‘v(erb)’, ‘a(djective)’, ‘r (adverb)’, ‘adjective s(atellite)’ or ‘p(article)’).
- Senses and forms in the model use the entry URI and add a fragment identifier. For forms for which there is no previous identifier in WordNet, we use CanonicalForm and Form-n where n is a number. For senses, the fragment is the index of the senses and the part of speech.
- Synsets are similarly are identified by a number consisting of 8 or 9 digits corresponding to offset codes in the WordNet database The 9 figure codes include an extra initial digit for part-of-speech, followed by a dash and the part of speech as a single letter.
WordNet JSON
In combination with the Global WordNet Association, we have developed a set of guidelines for creating wordnets as linked data. This can be done in either the LMF-compliant WN-LMF format or using the JSON-LD enabled schema below. The JSON-LD schema consists of the following elements
- Lexicon the root of a document should be a lexicon or a lexical entry that consists of a number of Lexical Entries
- A Lexical Entry is a single word or multiword expression as defined by lemon
- Each lexical entry must have exactly one Lemma it may have any number of other forms. Each of these must have a single Written Representation
- It may have other properties such as part-of-speech, see documentation at http://globalword.github.io/schemas/JSON-LD.md
- Any number of senses each of which should link to synsets and give a gloss plus any lexical relationships such as hypernym
Linking to the Interlingual Index
Once a wordnet has been created, its synsets should be linked into the Collaborative Interlingual Index which is maintained at http://globalwordnet.org/ili/. For up-to-date information about creating wordnets you should refer to the Global WordNet Association site. You may link to the ILI by choosing the appropriate links from the RDF graph as linking using the usual mechanism and as many resources will be linked to the ILI this guarantees the connectivity of your resource. You may also ask that your wordnet is indexed as part of the ILI, this request requires that:- Your resource has an license that allows redistribution with only attribution. Non-commercial and Share-A-Like license are not accepted.
- The resource is in WordNet LMF or WordNet JSON
- Every synset in your wordnet has a definition in English
- Every synset is either linked to the ILI as either a synonym, hypernym, antonym or meronym
- You do not create any duplicates of concepts already in the ILI (this is checked by automatic methods)
- Definitions are written according to the quality guidelines on the Global WordNet Assocation webpage