Linked Data generation process
Technical details
In order to convert BabelNet data into RDF format we need to:
- Read the original data: BabelNet’s data, originally stored within Lucene indexes, were accessed through BabelNet’s API and translated into RDF triples through the Jena API. The conversion module iterates over the Babel synsets and flushes converted data into data chunks (20k appeared to be a good setting).
- Convert the data into RDF: serialisation format is n-triples (best for huge data sets), and files are printed in compressed format (gz was chosen, since bz2 is not supported by virtuoso) so that the export was compatible with virtuoso loading capacities. The resource is exported into different files according to type of license. The distribution of triples under different licenses is handled via different (Jena) models.
- Load data into a Virtuoso server: after the RDF data has been generated, we installed and configured a Virtuoso server and finally loaded the file into the server.
Data modelling and conversion
We first provide a general picture which will help the reader throughout the guidelines and serves as a graphic representation of the main entities and the associated properties involved.
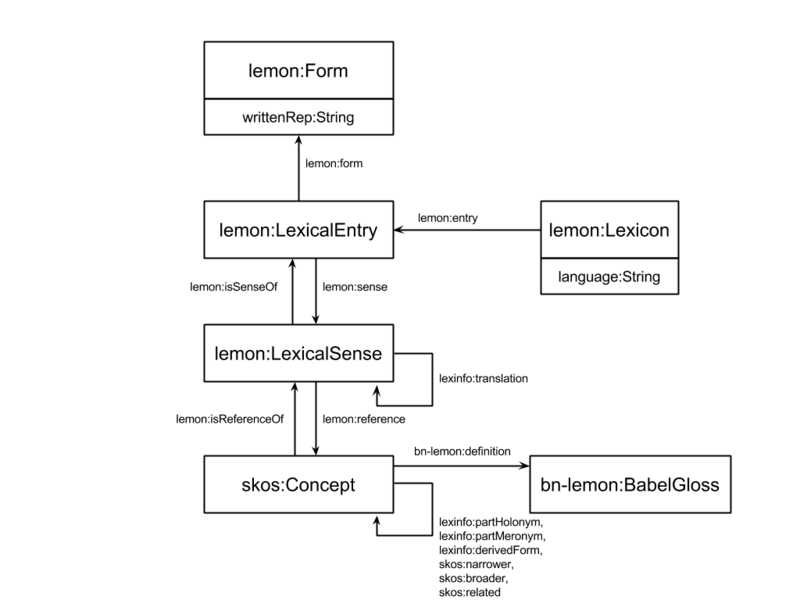
In the following we list the entities and properties chosen for representing the respective pieces of information (words, senses, glosses, etc.), with a brief description and an example. We addressed issues like:
- How do I model my own custom lexicon?
- How do I model word senses and the mapping between a lexical entry in my resource and its senses?
- How do I model common-usage and/or custom relationships between senses?
- How do I insert additional information into the model, such as textual definitions, concept attributes, etc.?
How to model a multilingual lexicon?
Item(s) to model: BabelNet implicitly provides a large multilingual lexicon.
Our solution: The closest entity in the lemon model is lemon:Lexicon. The RDF resource consists of a set of Lexicons (lemon:Lexicon), one per language, seen as containers of words. Currently BabelNet supports 271 languages, so BabelNet-lemon includes 271 lemon:Lexicons.
Issues: lemon:Lexicon forces us to work on a language-by-language basis, whereas in BabelNet this distinction does not need to be made explicit, as BabelNet is merely a collection of Babel synsets, i.e. multilingual synsets, and their relations.
How to model word forms and lemmas?
Item(s) to model: BabelNet contains lemmas as elements of its Babel synsets.
Our solution: Lexicons gather Lexical Entries (lemon:LexicalEntry) which comprise the forms of an entry in a certain language (in our case: words of the Babel lexicon). For example the English noun “plane” is encoded as follows:
We note that instead of generating new lexical entries, it could be possible to point to existing entries in some lexical resource (such as Dbnary) which already contains all the information associated with the lexical entry, thus avoiding redundancy of information in BabelNet-lemon.
Lexical Forms (lemon:Form), instead, encode the surface realisation(s) of Lexical Entries (in our case: lemmas of Babel words). For instance, the English canonical form "plane" is encoded as:
Issues: BabelNet does not currently provide all word forms for a lemma, resulting therefore in a duplication of information where each lemon:LexicalEntry (already lemmatized) is associated with its canonical lemon:Form. This is not necessarily an issue, since it is not very clear whether including all the possible morphological forms is truly desirable or not from a lexicographic point of view. Since many languages (e.g., Spanish, Italian and, even worse, Russian or Turkish) do easily spawn tens of different forms for each lemma, the resource would quickly be overwhelmed with too many forms.
How to model a word sense?
Item(s) to model: Babel synsets are sets of word senses expressed in different languages (called Babel senses).
Our solution: Lexical Senses (lemon:LexicalSense) represent the usage of a word in a given language as reference to a specific concept (in our case: Babel senses). For instance, the first sense of "plane" in BabelNet is encoded as:
Issues: in order to reduce the amount of redundancy, we decided to lump together senses of the same word - i.e., expressing the same concept - in the same language but obtained from different sources (e.g. plane from OmegaWiki and WordNet in the above example). As a result, multiple source and license information is listed for the same Lexical Sense.
How to model sense translations?
Item(s) to model: senses which are translations of other senses within a given Babel synset.
Our solution: Senses (modeled as lemon:LexicalSense) might also have translations into other senses in other languages. The lemon model alone does not provide a property for expressing this information, so we resorted to the relation lexinfo:translation within the LexInfo ontology model. For example, the fact that the first English sense of "plane" http://babelnet.org/rdf/plane_EN/s00001697n is translated into the French sense http://babelnet.org/rdf/avion_FR/s00001697n is encoded as:
LexInfo is an ontology which describes linguistic information and has been used in BabelNet-lemon to represent various linguistic information, such as translation relations and more specific relation types such as meronymy or holonymy.
Issues: A first issue concerns whether including the relation lexinfo:translation is essential or not. Within a Babel synset any two senses (in two different languages) are always the translation of each other. For example, if you consider the Babel synset with ID bn:00000356n, the two senses dwelling (in English) and abitazione (in Italian) both belong to the synset and are each the translation of the other; this does not happen for these two senses only, but in general for all the pairs of senses with different languages in the same synset. This fact points out that this information could actually be derived as follows: whenever a system has (i) two lemon:LexicalSenses which (ii) belong to the same skos:Concept and which (iii) have a different lemon:language, then the system can automatically infer that the two senses are in fact one the translation of the other. This argument undermines thus the necessity of such a translation relation and highlights the possible problem of redundancy. However, having the translation relation could also be a benefit for two reasons: first, because the information is explicit in the resource and no inference would be needed at all; second, because future, subsequent releases of the lexical resource could also refine this relation and, in that case, the specification of the translation relation would be unavoidable.
A second issue concerns the provenance and the confidence information associated with each translation relation. BabelNet’s translations come from explicit resource information (e.g., Wikipedia interlanguage links) or from the automatic translations of semantically annotated corpora. We do have a confidence for each of these translations together with the source of the original text. This produces already a distinction regarding the quality and the origin of the translation information. So, despite the resource could potentially include it, the information about translation confidence (was it humanly or automatically produced? by whom? if automatic, with what confidence score?) and translation provenance (what text(s) does the translation come from? who translated and with what tool?) are currently missing.
In addition, translations could be validated through human annotations over time (and thus made more authoritative) and, more in general, the resource could accommodate additional translations coming from different inputs, at different times, from different sources. The general scenario is then that of a set of provisional translations which have different characteristics about quality and provenance. At the moment the translation information is strictly bound to the Babel sense it refers to and models the probability of the sense to belong to a synset. In case of such a general scenario, a best practice is to reify the translation relation into an entity and then attach as many metadata information as needed to the reified relation. The translation entity should in fact model characteristics of the translation process rather than of the target lexical entry itself. In order to account for all such information, the International Tag Set (http://www.w3.org/TR/its20/) stands out as a very good candidate. Thus, to include information about the provenance of a given annotation we could adopt the its:annotatorsRef attribute which "provides a way to associate all the annotations of a given data category within the element with information about the processor that generated those data category annotations" (from http://www.w3.org/TR/its20/#provenance). This information should then also be paired with a confidence score (its:mtConfidence attribute) certifying the accuracy of the translation that the translation processor (either an automatic tool or a physical person) has provided (see http://www.w3.org/TR/its20/#mtconfidence).
Another possible design choice to represent explicit translations as linked data is to consider using the lemon translation module (http://linguistic.linkeddata.es/def/translation/) which "consists essentially of two OWL classes: Translation and TranslationSet. Translation is a reification of the relation between two lemon lexical senses. The idea of using a reified class instead of a property allows us to describe some attributes of the Translation object itself" (from http://www.w3.org/community/ontolex/wiki/Translation_Module, cf. http://lemon-model.net/lemon-cookbook/node18.html).
Future conversions of BabelNet might well include all these additional metadata information with the most suitable model entities.How to encode concepts?
Item(s) to model: Babel synsets, i.e. sets of multilingual lexicalizations denoting a certain concept, are the core elements of BabelNet.
Our solution: We used SKOS Concepts (skos:Concept) to represent ‘units of thought’ (in our case: Babel synsets) on the basis of its definition and its similar previous usage to model similar objects in other RDF resources (e.g. WordNet). For example, the Babel synset which contains the first sense of plane, i.e., http://babelnet.org/rdf/s00043466n, is encoded as:
Issues: versioning is currently an issue, as we do not have a mechanism to keep track of previous versions of the same synset, if any, and when (i.e. from which version) the synset started to exist in BabelNet.
How to encode concept attributes?
Item(s) to model: associated with a Babel synset, BabelNet has the notion of "concept type", i.e., a type label which declares the concept either as a 'Concept' (e.g., "singer") or a 'Named Entity' (e.g., "Frank Sinatra").
Our solution: to this end we provided a new property in our own BabelNet-specific RDF vocabulary, called bn-lemon:synsetType. In the above example, the fact that the previous synset represents a concept is encoded by:
Issues: since we could not find any similar notion in the models used, we decided to introduce a new property. In general, since attributes can bear arbitrary information which might or might not fit pre-defined entities and properties, it is not possible to give a general guideline in this case and it is thus responsibility of the designer to find the best solution, on a case-by-case basis.
How to model a concept gloss?
Item(s) to model: BabelNet provides multiple glosses in several languages for each Babel synset. A gloss is a short explanatory sentence of a concept. For example the English OmegaWiki definition for the first sense of plane in BabelNet is "A powered heavier-than-air aircraft with fixed wings that obtains lift by the Bernoulli effect and is used for transportation".
Our solution: we defined a new entity, called bn-lemon:BabelGloss, which encodes a textual definition associated to a Babel synset. The property bn-lemon:definition binds synsets to their gloss(es). The fragment of text below is intended to show an example of the encoding of an English BabelGloss. Note that additional information such as the reference language (lemon:language) and the source of the definition (dc:source) are also attached to the gloss.
Issues: since there might well be more than one gloss in a certain language for a given Babel synset (coming from different sources, such as Wikipedia or OmegaWiki), bn-lemon:BabelGloss’s URIs include an incremental integer. Another choice would have been to include a source identifier (‘Wiki’, ‘Omega’, ‘WordNet’, etc.) within the gloss’s URI (such as, for instance, bn:s00001697n_Gloss_Wiki_EN or bn:s00001697n_Gloss_Omega_EN).
How to model semantic relations?
Item(s) to model: BabelNet comes with a very high number of semantic relations, also characterized by their semantic type. Relation types are basically inherited from WordNet and include, among others, hypernymy (is-a), hyponymy (has-a), meronymy (is-part-of), holonymy (has-part) and even derivationally related forms (such as 'solve#v' for 'solution#n'). Most of the edges, though, lack a clear typing and are labelled as mere "related-to" edges.
Our solution: In order to describe the several types of semantic relations that a synset is involved in, we exploited both the LexInfo and the SKOS models. In fact, relations such as meronymy, holonymy and derivationally related forms can be found in the LexInfo model (lexinfo:partMeronym, lexinfo:partHolonym and lexinfo:derivedForm, respectively), while all the other types, such as hypernymy, hyponymy, and the more general un-typed relatedness, have been drawn from the SKOS model (skos:narrower, skos:broader and skos:related, respectively). As regards the above example, we show an excerpt encoding several semantic relation types:
Issues: we also note that there is another type of relation encoding the notion of 'equivalence' between concepts across different resources (such as the BabelNet synset "bn:00001697n" and the DBpedia concept http://dbpedia.org/page/Airplane). We thus decided to describe this notion of equivalence by means of the skos:exactMatch property; note, however, that a similar choice could have been made in favor of the owl:sameAs property or by relaxing the type of matching with skos:closeMatch, rdf:seeAlso, etc.
How to encode resource names?
Item(s) to model: Resource identifiers can be encoded by using either URIs or IRIs, strings which uniquely identify resources in a model. URIs facilitate automatic elaboration of linked data, whereas IRIs improve readability for human end users. URIs can either be descriptive -- encoding as much meaning as possible (e.g., bn:Haus_n_DE which represents the German lexical entry for “House”) -- or opaque -- encoding names which do not convey the content of the resource identifier (e.g., the URI for synset with ID bn:00024498n is bn:s00024498n which does not truly say much about the synset’s content). On the other hand, IRIs preserve a language’s specific alphabet but at the same time hinder readability to non-native speakers. For example the following IRI “bn:樓宇_ZH/s00044994n” encodes the sense of House in Chinese, but a non native speaker can have a hard time understanding this. An additional dimension of the naming scheme is represented by the choice of whether to include the language tag in the resource identifier (as in http://babelnet.org/rdf/樓宇_ZH/s00044994n) or directly in the host name (e.g., http://zh.babelnet.org/rdf/樓宇/s00044994n).
Our solution: use both URIs and IRIs in order to have the highest degree of flexibility and expressivity. Since our lexical resource is not divided up into different datasets, the option to provide the language identifier as part of the host name was not practical (that is, we do not have a subdomain per language, en.babelnet.org, zh.babelnet.org, fr.babelnet.org, etc.); so we decided to include the language identifier as part of the URI/IRI. For instance, the previous IRI http://babelnet.org/rdf/樓宇_ZH/s00044994n encodes the language by means of the ‘ZH’ suffix, concatenated with the sense string 樓宇.
Issues: The current usage of resource identifiers is not unified yet, so that certain entities, such as Babel synsets and BabelGlosses, are encoded with URI, while other language-specific entities, such as BabelSenses and LexicalEntries, use IRI. Generally speaking, whenever it was possible to do so, we preferred meaningful URIs (e.g., bn:Haus_n_DE); in other cases we came up with IDs which uniquely identified the resource. As regards Babel synset URIs, we preferred to mantain the synset identity quite general and avoided to promote any sense as the main sense for that synset. As regards glosses, the gloss URI encodes the synsetID the gloss refers to, the language and an incremental integer which differentiates between glosses of the same language (e.g., the synset for the first sense of “home” has 3 English glosses coming from different sources, identified by bn:s00044994n_Gloss1_EN, bn:s00044994n_Gloss2_EN, and bn:s00044994n_Gloss3_EN).